
(*주의* 웹크롤러의 경우 다른 사람의 저작물을 저장하여 사용하게 되기 때문에 상업적 이용 시 문제가 될 수 있음)
네이버 웹툰에서 많은 웹툰이 게재되어 있다.
이미지를 저장하는 웹 크롤러를 교육용으로 만들어봤다.
웹툰 별로 정보를 가져올 수 있지만 이미지만 추출 한 후 이미지를 컴퓨터에 저장하는 크롤러를 만들고자 한다.
파일처리가 들어가기 때문에 어렵다고 생각할 수 있지만, 파이썬의 경우 파일처리가 어렵지 않기 때문에 20줄 이하로 만들 수 있다.

네이버 웹툰 이미지 저장 크롤러
- requests를 활용하여 내가 이미지를 가져오고자 하는 곳의 정보를 가져오기
- 해당 정보를 기준으로 BeautifulSoup으로 해당 위치의 이미지 주소를 찾기
- img 태그를 찾아서 scr 속성 안에 쓰여져 있는 정보를 가져오면 이미지 주소가 된다.
- 해당 이미지 URL을 requests.get( )으로 content를 가져오고, 해당 content를 파이썬 파일 처리로 저장한다.
- 참고로 파일명에 특수 문자가 있는 경우 제대로 저장이 되지 않기 때문에 글자 전처리를 해야 한다.
- file = open("img/+fname+".jpg" , "wb")
- img 폴더에 전저리한 fname(파일명)으로 jpg확장자로 저장하라는 명령, wb는 바이너리파일을 쓰겠다는 파일 모드로 지정한 것, 이미지를 저장하고자 하는 경우에는 wb 모드를 명시해 줘야 한다.
- file.write( img_con)
- 지정한 파일명에 이미지 주소로 가져온 content를 쓰는 명령어
- file.close( )
- file 처리 완료 후 파일을 닫아 주는 명령어
import re
import requests
from bs4 import BeautifulSoup
url = "http://comic.naver.com/webtoon/weekday.nhn"
html = requests.get(url)
bs_html = BeautifulSoup(html.content,"html.parser")
thumb = bs_html.find_all("div",{"class":"thumb"})
for toon in thumb:
img = toon.find("img")
webtoon_info = re.findall('<img.+? src=.(.+?). title="(.+?)"',str(img))
img_con = requests.get(webtoon_info[0][0]).content
fname = webtoon_info[0][1]
fname = fname.replace("?","")
fname = fname.replace(".","")
fname = fname.replace("!","")
file = open("img/"+fname+".jpg","wb")
file.write(img_con)
file.close()
print(webtoon_info[0][0], "이미지 저장 완료")
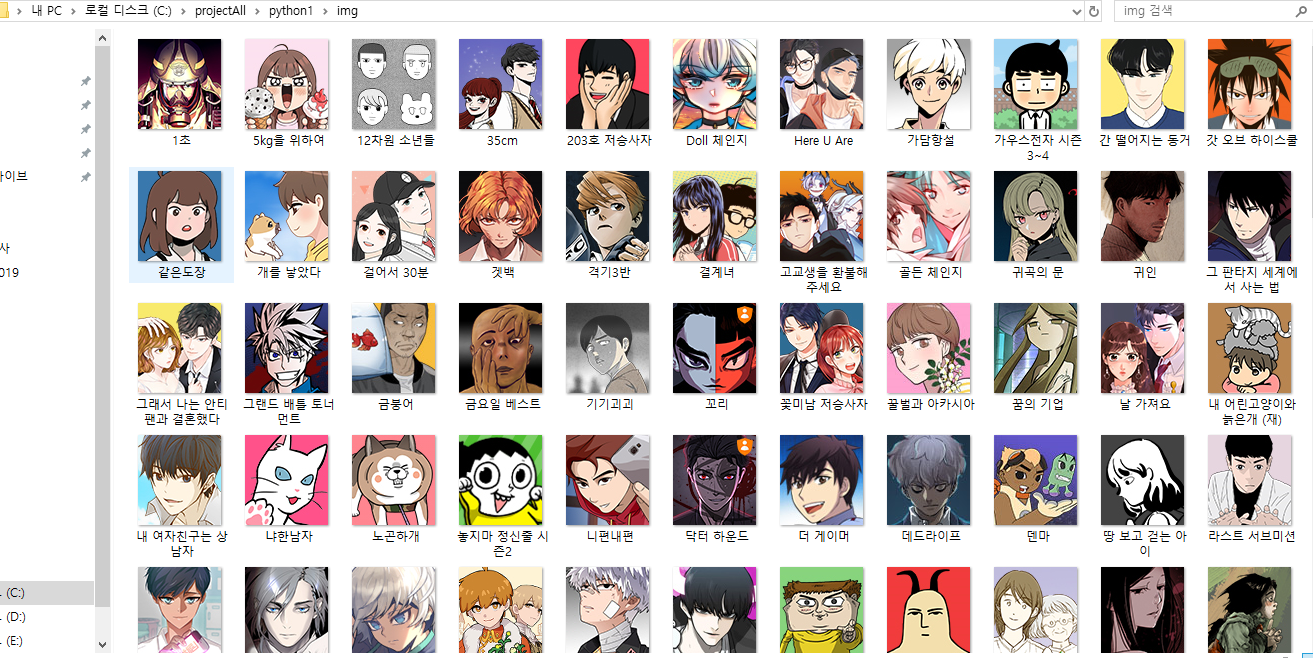
(결과)

ㅇ 지정한 폴더에 저장된 이미지(컴퓨터)
- 파이썬으로 이미지 저장이 완료 된 후 해당 위치의 폴더로 이동하면 이미지가 저장된 것을 확인할 수 있다.
- 다시한번 이야기 하지만 해당 이미지의 경우 저작권이 네이버에 있기 때문에 상업적 용도로 사용 시 문제가 될 수 있음을 참고해야 한다.
반응형
'Python > 파이썬 크롤링 예' 카테고리의 다른 글
| 파이썬 웹 크롤러 : 네이버 이미지 검색 저장 프로그램 (0) | 2019.05.10 |
|---|---|
| 파이썬 웹 크롤러 만들기 : 기상청 RSS 도시 예보 (0) | 2019.05.09 |
| 파이썬 웹 크롤러 만들기 : 네이버 뉴스 가져오기 (0) | 2019.05.09 |



댓글